论文阅读:Mitigating Large Language Model Hallucination with Faithful Finetuning——通过忠诚微调减轻大型语言模型幻觉
在这项工作中,我们引入了一种名为Faithful Finetuning(F2)的新颖方法,它通过在微调期间精心设计的损失函数显式地对忠实问答过程进行建模。
原文地址:[2406.11267] Mitigating Large Language Model Hallucination with Faithful Finetuning (arxiv.org)
背景(WHY?为什么需要这个技术?)
幻觉问题
是什么:幻觉(Hallucinations)是指语言模型在生成文本时出现的不真实、与事实不符的现象,即使文本在语法和语义上看起来是流畅和合理的。
分类
- 外源性幻觉:包含事实错误或不存在的实体
- 内源性幻觉:虽然事实正确但与任务无关
产生原因:幻觉可能由多种因素引起
- 模型对自身输出的过度依赖
- 为追求文本流畅性而牺牲准确性
- 模型训练阶段累积的知识所固有的不确定性。
减轻幻觉的策略:多关注于检测幻觉而非生成过程中的减轻
可以在不需要进行广泛的结构修改或全面重新训练模型的情况下,显著减轻幻觉。(Detecting and Mitigating Hallucinations in Multilingual Summarisation)
- 隐式编辑LLMs的行为(通过间接的方式影响或LLM的生成过程或决策,而这些改变并不是直接对模型的参数或架构进行调整)
- 自我完善(Self Refinement):通过反馈和推理机制,模型在生成回答后能够进行自我评估和改进。
- 提示调整(Prompt Tuning):调整提示以改善模型的响应,这涉及到在输入中加入特定的指导性语言,以引导模型生成更准确的回答。
- 在解码过程中抑制输出不诚实结果的倾向(输出检测)
- 隐式编辑LLMs的行为(通过间接的方式影响或LLM的生成过程或决策,而这些改变并不是直接对模型的参数或架构进行调整)
忠诚微调 Faithful Finetuning(F2)
是什么:通过在微调过程中明确设计损失函数来显式地对忠诚问答过程进行评估。通过改善LLM本身的缺陷来减轻幻觉
贡献:
多目标分解: 将传统的问答目标分解为内部事实检索和事实基础的问答两个明确的子目标。
针对性微调: 设计了一种针对性的微调方法,专注于通过实体基础和注意力基础启发式识别的热点。
幻觉倾向层的选择: 选择LLM结构中容易幻觉的层进行特定的微调,以减少幻觉的发生。
显式损失设计:通过精心设计的损失函数来提高模型的忠实度和真实性,这种方法在提高LLMs的可信度方面显示出了有效性。
忠诚微调 Faithful Finetuning(WHAT? 什么是诚实微调?)
框架结构
- 提高问答(QA)模型的忠实度而明确两个子目标
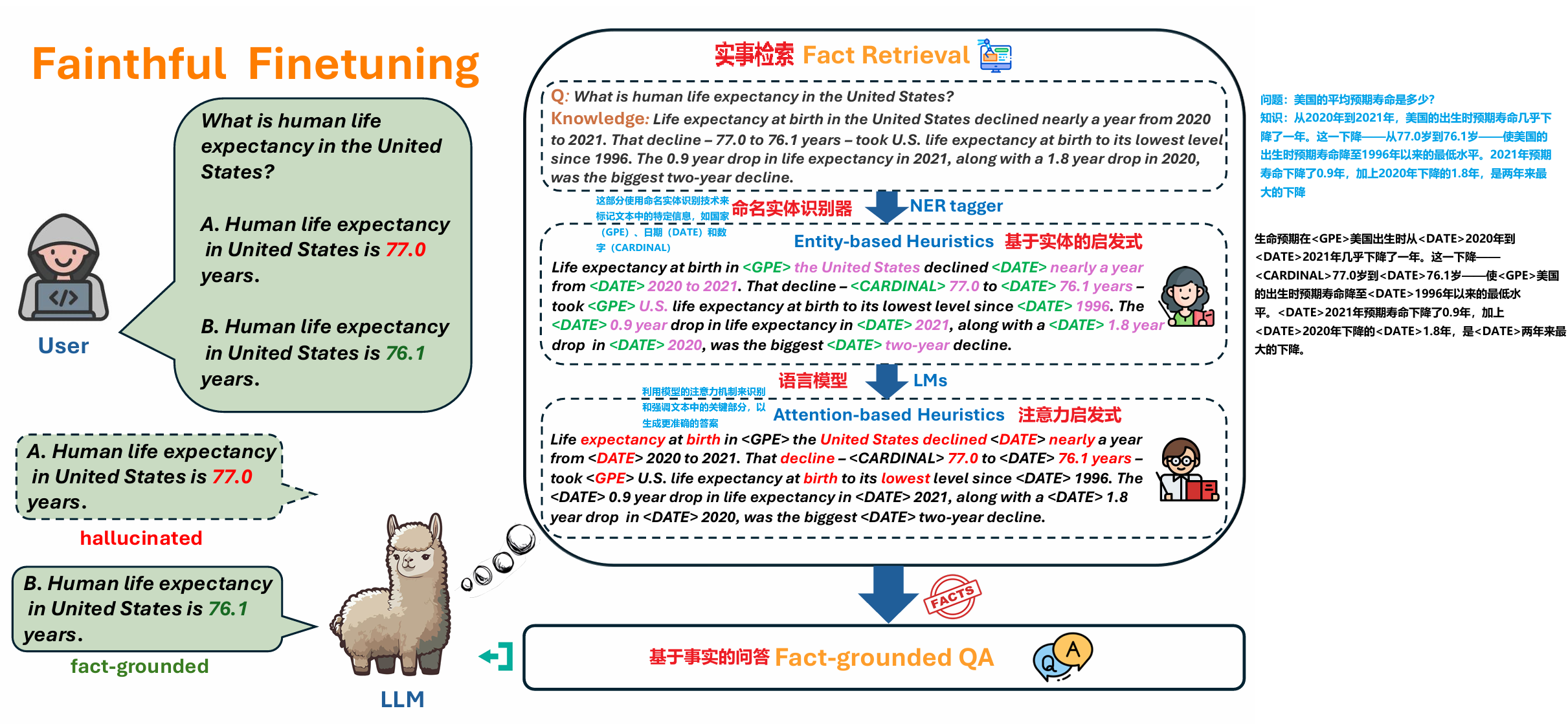
- 内部事实检索( Internal Fact Retrieval:):训练模型有效地检索并利用其内部知识来产生忠实的答案。
- 事实基础的QA( Fact-grounded QA):训练模型提供以事实信息为基础的答案。
- 从输出概率的角度进行幻觉行为的观察,在事实检索期间对幻觉倾向区域进行针对性训练
- F2利用加权目标和针对性微调,关注包括幻觉倾向的热点,如span和层。这些加权目标强调了LLMs倾向于产生幻觉的跨度。
- 示意图
- 提高问答(QA)模型的忠实度而明确两个子目标
具体实现
多目标分解以实现忠实的问答
传统的QA目标(Vanilla QA Objective):通过优化交叉熵损失𝐿𝑄𝐴(𝜙)LQA(ϕ)来增加给定问题𝑞的条件概率𝑎
𝐿𝑄𝐴(𝜙)=−𝐸(𝑘,𝑞,𝑎)∼𝐷𝐹𝑄𝐴[log𝜏𝜙(𝑎∣𝑞)]LQA(ϕ)=−E(k,q,a)∼DFQA[logτϕ(a∣q)]用于衡量模型预测的概率分布与真实答案的概率分布之间的差异
𝐸:期望值,这里指在整个数据集𝐷𝐹𝑄𝐴上的平均。 (𝑘,𝑞,𝑎):一个训练实例,其中𝑘是与问题𝑞相关的事实基础,𝑎是对应的答案。 𝐷𝐹𝑄𝐴:QA任务的训练数据集。 𝜏𝜙(𝑎∣𝑞):给定问题𝑞时,由参数𝜙决定的自回归语言模型生成答案𝑎的概率分布。 log:自然对数,用于损失函数中以增加对错误预测的惩罚。
实事检索目标(Fact Retrieval Objective):增强LMs访问其内部记忆并在自我包含的方式下基于问题𝑞检索相关和事实知识𝑘的能力
𝐿𝑅(𝜙)=−𝐸(𝑘,𝑞,𝑎)∼𝐷𝐹𝑄𝐴[log𝜏𝜙(𝑘∣𝑞)]LR(ϕ)=−E(k,q,a)∼DFQA[logτϕ(k∣q)]
τΦ(k∣q) 表示在给定问题 𝑞 下,模型参数 Φ 所检索的事实 𝑘的概率分布。
事实基础的问答FQA目标(Fact-grounded QA Objective):用来鼓励语言模型生成与从其内部记忆检索到的事实𝑘紧密相关的答案𝑎
损失函数定义为:𝐿𝐹𝑄𝐴(𝜙)=−𝐸(𝑘,𝑞,𝑎)∼𝐷𝐹𝑄𝐴[log𝜏𝜙(𝑎∣𝑞,𝑘)]LFQA(ϕ)=−E(k,q,a)∼DFQA[logτϕ(a∣q,k)]
𝜏𝜙(𝑞∣𝑘) 是给定事实𝑘k时,问题𝑞的概率,这可以被理解为问题与事实之间的相关性。
结合𝐿𝑅(𝜙),𝐿𝑅(𝜙)+𝐿𝐹𝑄𝐴(𝜙)最小化联合损失,使得模型在给定问题时能够检索正确的事实,并且基于这些事实生成准确的答案。𝐿𝑅(𝜙)+𝐿𝐹𝑄𝐴(𝜙)=−𝐸(𝑘,𝑞,𝑎)∼𝐷𝐹𝑄𝐴{log[𝜏𝜙(𝑎∣𝑞,𝑘)×𝜏𝜙(𝑞∣𝑘)]}LR(ϕ)+LFQA(ϕ)=−E(k,q,a)∼DFQA{log[τϕ(a∣q,k)×τϕ(q∣k)]}(?)
针对性训练幻觉热点(Targeted Training on Hallucination Hotspots)
针对性微调:专注于模型在生成回答时特别容易出错的部分。 幻觉热点:指在训练数据中,模型特别容易产生不真实或与事实不符回答的文本标签(span)
实体基础启发( Entity-based Heuristics):利用加权交叉熵(Weighted Cross Entropy, WCE)损失函数
Pagnoni等人和Kryscinski等人的研究表明,在文本生成任务中,实体是最常被幻觉或虚构的词汇类型。这一发现与人们的直觉相符,即在评估生成文本的真实性时,人们倾向于主要关注关键词。
𝐿𝑊𝐶𝐸(𝜙,𝑤,𝐷)=−𝐸(𝑘,𝑞,𝑎)∼𝐷[𝜏𝑊𝐶𝐸(𝑘∣𝑞,𝑤)]LWCE(ϕ,w,D)=−E(k,q,a)∼D[τWCE(k∣q,w)], 其中𝜏𝑊𝐶𝐸(𝑘∣𝑞,𝑤)=∑𝑖=1∣𝑘∣𝑤𝑖log𝑝(𝑘𝑖∣𝑞,𝑘1,…,𝑘𝑖−1)τWCE(k∣q,w)=∑i=1∣k∣wilogp(ki∣q,k1,…,ki−1)模型给定问题 𝑞和权重 𝑤时,事实 𝑘的条件概率分布
𝐿𝑊𝐶𝐸(𝜙,𝑤,𝐷)这是损失函数的一般形式,上标 𝑊𝐶𝐸 表示这是加权的版本,即某些输出的概率会受到比其他概率更大的权重影响。 𝜙表示模型的参数。 𝑤是权重向量,用于在损失函数中加权不同的概率输出。 𝐷是训练数据集。 𝐸(𝑘,𝑞,𝑎)∼𝐷 表示对从数据集 𝐷 中抽取的样本 (𝑘,𝑞,𝑎)取期望。 ∑表示对 𝑘 中的每个元素 𝑘求和。 𝑤𝑖是与元素 𝑘𝑖相关的权重。 log 𝑝(𝑘𝑖∣𝑞,𝑘1,…,𝑘𝑖−1) 是在已知问题 𝑞 和先前事实 𝑘1,…,𝑘𝑖−1 的条件下,元素 𝑘𝑖的对数概率。
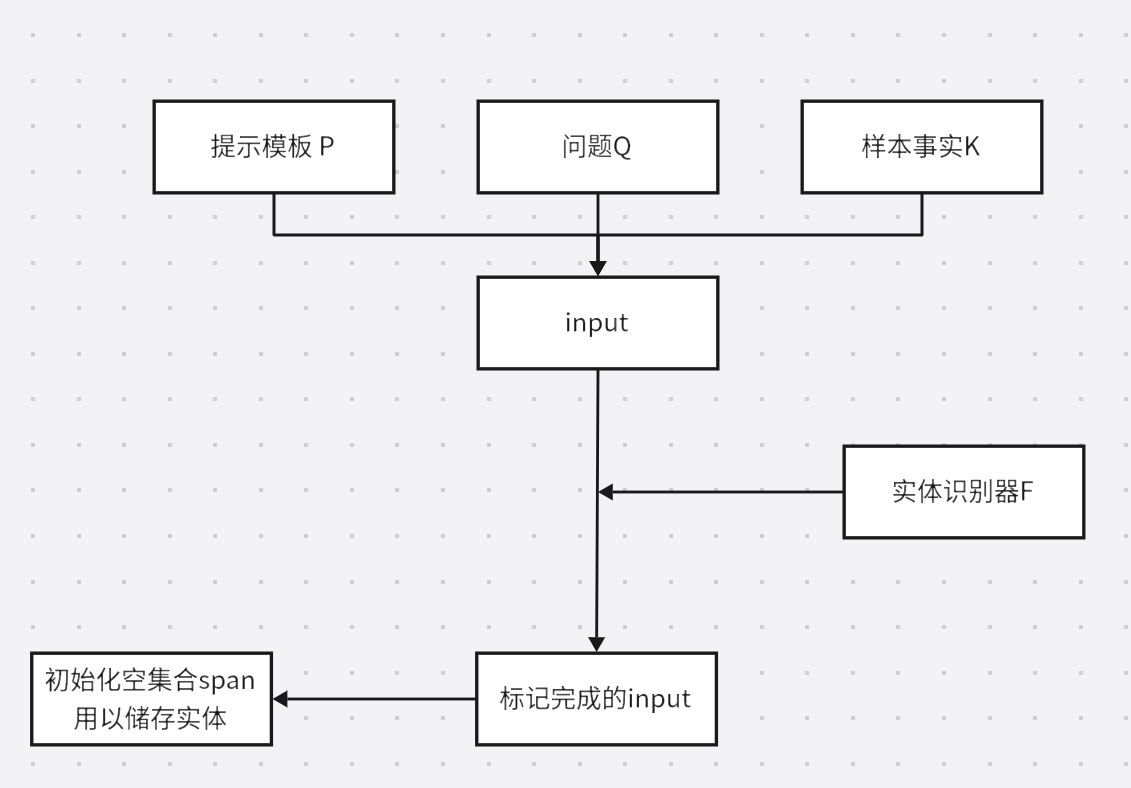
使用 Spacy 识别命名实体标签(NER)
𝐿𝐸(𝜙)=𝐿𝑊𝐶𝐸(𝜙,𝑤𝑒𝑛𝑡,𝐷𝐹𝑄𝐴)LE(ϕ)=LWCE(ϕ,went,DFQA)——𝐿𝑊𝐶𝐸LWCE 的一个特例,其中权重 𝑤 被特定为 𝑤𝑒𝑛𝑡went,这是基于实体的权重。
𝐷𝐹𝑄𝐴 是用于问答任务的事实基础数据集。
𝑤𝑒𝑛𝑡𝑖={𝛼,if 𝑖∈span𝑒𝑛𝑡1,otherwisewenti={α,1,if i∈spanentotherwise
如果索引 𝑖i 在实体跨度 span𝑒𝑛𝑡 内,权重被设为 𝛼(一个大于1的系数,表示增加的重要性)。如果索引 𝑖不在实体跨度内,权重则为1,表示这个元素的重要性是正常的。
生成的过程:
最后得到了具有实体基础启发的最终损失设计(loss design):𝐿𝐸𝑡𝑎𝑔(𝜙)=𝐿𝑊𝐶𝐸(𝜙,𝑤𝑒𝑛𝑡,𝐷𝐹𝑄𝐴𝑡𝑎𝑔)LEtag(ϕ)=LWCE(ϕ,went,DFQAtag)
注意力基础启发式(Attention-based Heuristics)
具有高注意力得分的跨度赋予更高的权重
𝐿𝐴(𝜙)=𝐿𝑊𝐶𝐸(𝜙,𝑤𝑒𝑛𝑡,𝐷𝐹𝑄𝐴)LA(ϕ)=LWCE(ϕ,went,DFQA),其中𝑤𝑎𝑡𝑡𝑛𝑖={𝛼,if 𝑖∈span𝑎𝑡𝑡𝑛1,otherwisewattni={α,1,if i∈spanattnotherwise
𝑠𝑝𝑎𝑛𝑎𝑡𝑡𝑛spanattn生成过程:
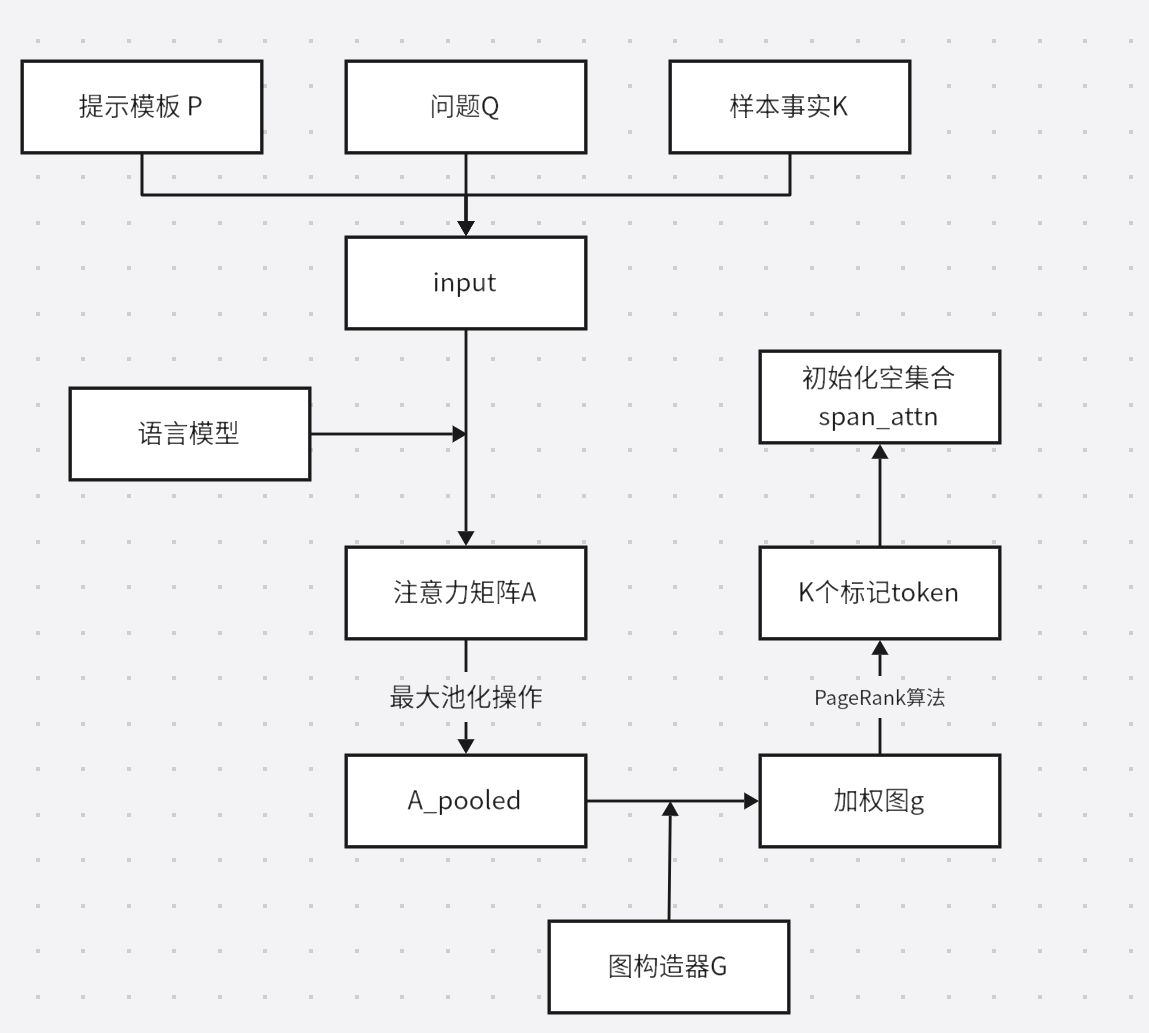
最大池化,可以从注意力矩阵中提取每个输入标记在生成所有输出标记时的最大注意力权重。这有助于识别文本中的关键部分,如实体或重要概念。最大池化的结果被用来构建一个加权图。
PageRank是一种用于衡量网络中节点重要性的算法,被用来衡量文本中各个标记的重要性,基于它们在整个文本结构中的连接和相互作用。
合并权重:将𝑤𝑎𝑡𝑡𝑛wattn和𝑤𝑒𝑛𝑡went合并为𝑤𝑎𝑡𝑡𝑛∪𝑒𝑛𝑡wattn∪ent
- 𝐿𝐴∪𝐸(𝜙)=𝐿𝑊𝐶𝐸(𝜙,𝑤𝑎𝑡𝑡𝑛∪𝑒𝑛𝑡,𝐷𝐹𝑄𝐴)LA∪E(ϕ)=LWCE(ϕ,wattn∪ent,DFQA),其中𝑤𝑎𝑡𝑡𝑛∪𝑒𝑛𝑡𝑖={𝛼,if 𝑖∈span𝑎𝑡𝑡𝑛∪𝑒𝑛𝑡1,otherwisewattn∪enti={α,1,if i∈spanattn∪entotherwise
我们得到忠实微调中的最终微调目标形式
- 𝐿𝐹2𝑡𝑎𝑔(𝜙)=𝐿𝑄𝐴𝑡𝑎𝑔(𝜙)+𝐿𝐹𝑄𝐴𝑡𝑎𝑔(𝜙)+𝐿𝐴∪𝐸𝑡𝑎𝑔(𝜙)LF2tag(ϕ)=LQAtag(ϕ)+LFQAtag(ϕ)+LA∪Etag(ϕ),LtagQA和LtagFQA是使用标记训练集DtagFQA的前述损失LQA和LFQA
微调幻觉倾向层
- 采用了TruthX方法,仅对与幻觉最强烈相关的前10个模块进行微调,这些模块是通过在验证集上的探测精度确定的。
实验总结(HOW? 效果怎么样?)
- 数据集
- HaluEval、TruthfulQA、FACTOR
- 训练集(HaluEval)在领域上与测试集(TruthfulQA和FACTOR)完全不同。可以验证F2方法的鲁棒性。
- 评价指标
- MC1:在真实和虚假的参考答案集中,我们需要选择最佳的正确答案。MC1是通过语言模型是否将最高的可能性分配给最佳正确答案而不是错误答案来计算的,这是基于给定问题的情况。
- MC2:MC2是真实参考答案的总归一化概率。该分数是正确答案的概率质量。
- MC3:MC3是通过语言模型是否将更高的可能性分配给正确答案而不是错误答案来计算的。
- 对于FACTOR数据集,简单地使用选择准确率作为度量指标
- 对比基线方法
- 基础LLMs(BaseLLMs):Llama-2-7B
- 对比解码(Contrastive Decoding):CD、 DoLa、 SH2、ICD
- 表示编辑(Representation Editing):ITI、TrFr、TruthX、F2
测试结果
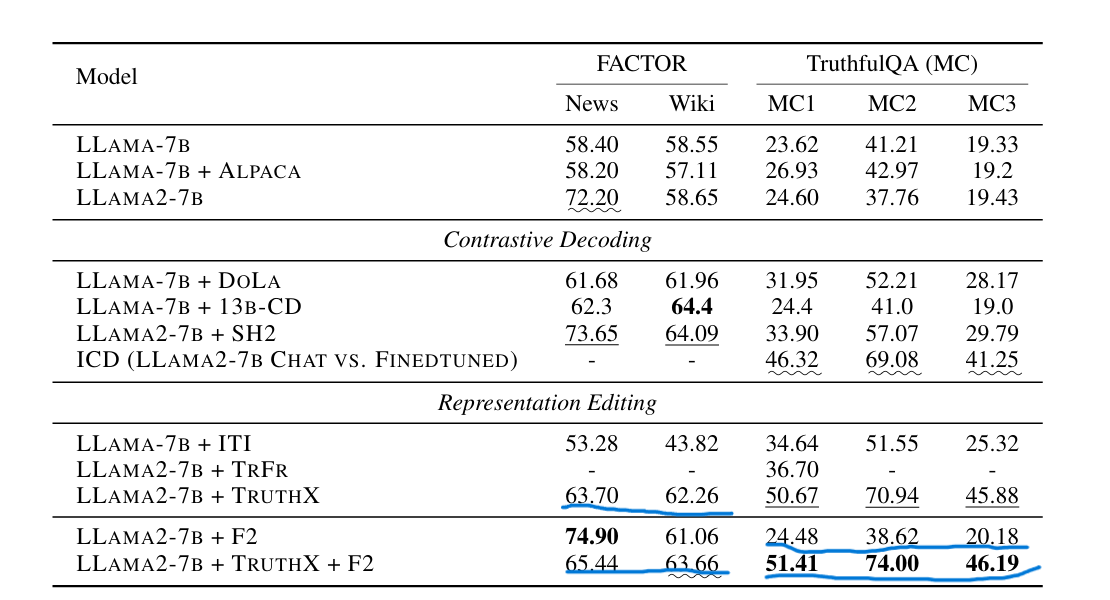
- 最高值用加粗表示,第二高值用下划线标注,第三高值用波浪下划线标注。
-
- TruthfulQA
- F2方法单独并不能像结果中显示的其他方法提供大的性能改进。这可能归因于LoRa微调是一种相对保守的模型优化方式,与表示编辑方法如ITI和TRUTHX不同。
- F2方法与TRUTHX方法可以互补,而不是相互冲突,且结合效果良好(或许可以和其他的表示编辑方法结合?)
- FACTOR
- LLAMA2-7B+TRUTHX+F2有效地缓解了LLAMA2-7B+TRUTHX在News子集上的性能下降,同时将Wiki的准确率从61.06提高到63.66,展示了F2方法的鲁棒性。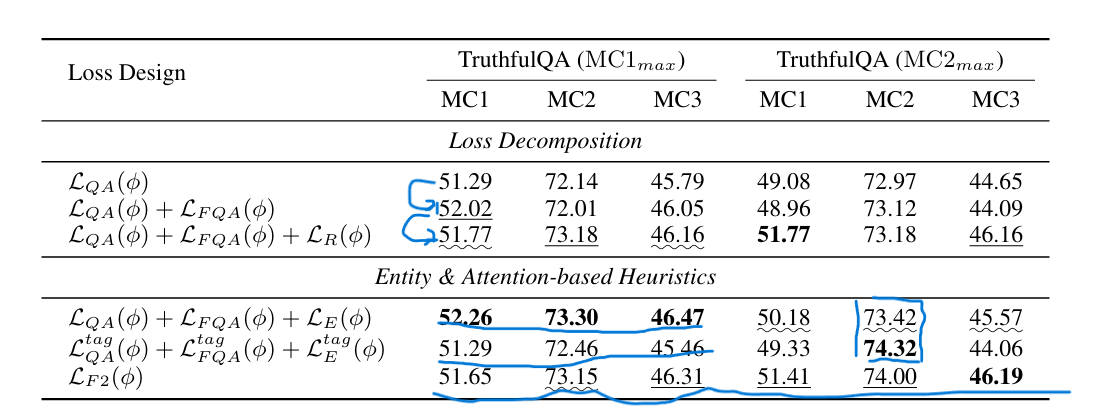
- 分解问答目标(LQA(ϕ) + LFQA(ϕ) + LR(ϕ))相比LQA(ϕ),分别额外提高了0.5和1.0个百分点,验证了所提出的多目标分解的有效性。
- LF2(ϕ)的结果表明,基于注意力的加权策略在所有三个指标中取得了平衡。(说服力?)
- 对大模型生成速度的影响是否需要测试?
