论文阅读:EEG-Defender : Defending against Jailbreak through Early Exit Generation of Large Language Models
尽管越狱提示可能产生与良性提示相似的输出logit,但在模型潜在空间中的初始嵌入倾向于与恶意提示的嵌入更为相似。利用这一发现,我们提出使用LLMs的早期Transformer输出作为检测恶意输入的手段,并立即终止生成。基于这一理念,我们引入了一个名为EEG-Defender的简单但重要的防御方法,用于LLMs。
WHY
解码防御的不足
目前基于解码的防御技术还不够充分。研究表明,现有的防御方法只能将针对越狱提示的攻击成功率(ASR)降低大约50%
LLM内不同层的作用
- 初始层专门用于触发特定任务。
- 中间层作为知识库,塑造输出的情感基调。
- 后续层是语言输出细化的地方。
关键假设鉴于语言只影响我们的传递方式,而不是表达的语义
假设LLMs在初始层识别功能和中间层访问存储知识时,对越狱和有害提示的处理方式相似。
可行性证明
两个假设
1. 越狱的机制是它们的嵌入在输出空间中从“有害”移向“良性”
2. LLMs的浅层可以区分越狱提示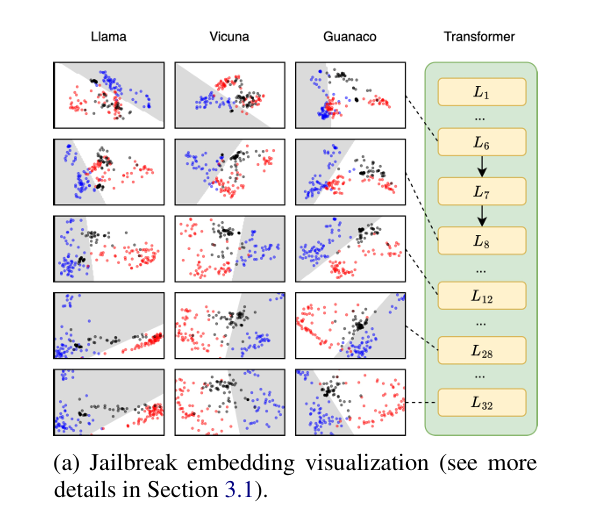
越狱提示(黑点)良性提示(蓝点)有害提示(红点)- 有害提示是直接请求有害或非法行为的提示。
- 越狱提示是复杂的,可能包括压抑性否定和虚拟语境,或对抗性后缀。良好对齐的LLMs可以拒绝简单的有害提示,但可能仍然接受越狱提示。
- 良性提示。这些是遵守道德准则的用户提示,请求LLMs提供帮助,而不违反任何规范。
数据集
从Alpaca Eval收集了60个良性提示,从AdvBench收集了60个有害提示。然后,我们评估了由GCG、AutoDAN、GPTFuzz)和Tap生成的60个越狱提示,所有提示均有效越狱。
结果
- 从模型的早期层(例如,第6层和第8层)开始,越狱提示的嵌入与有害提示的嵌入一致。
- 在中间层(例如,第12层),当LLMs检索信息时,越狱嵌入向良性嵌入轻微转移
- 到了更高层(例如,第28层和第32层),它们与良性嵌入越来越一致。
- 最终,越狱嵌入要么分布在整个空间中(如Llama2所见),要么与决策边界一起分布(如Vicuna和Guanaco所见),这使得模型在识别越狱状态时变得复杂。
浅层更好区分越狱的证明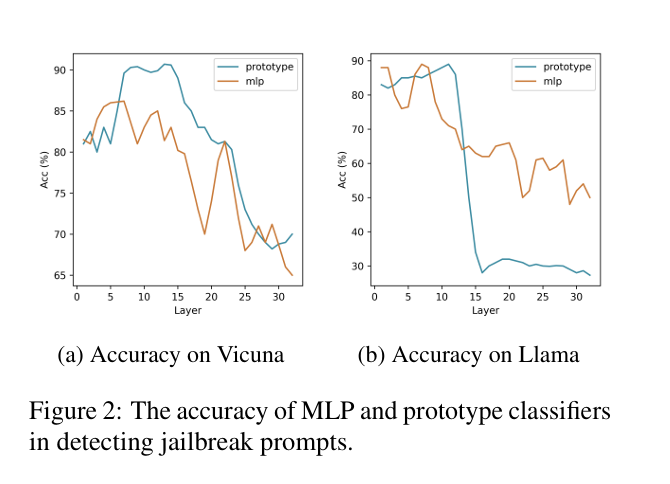
收集了所有层的良性提示和被拒绝的有害提示的嵌入,并分别训练了32个MLP分类器和32个原型分类器,对应于每层的输出。使用这两组分类器来识别模型无法拒绝的越狱提示。
结果
早期层收集的分类器比从后来层收集的分类器表现得更好。
在区分越狱提示方面,两种模型的准确率在第十二层之前都超过了80%。更应该关注早期和中间层空间而不是输出空间。
==利用良性提示和被拒绝的有害提示作为每个层输出的锚点。如果来自早期和中间层的嵌入与有害锚点足够相似,模型将拒绝用户的请求。==
主要贡献
- LLMs的类人生成过程。 研究揭示了LLMs的生成过程与人类语言组织相似。(生成概念->调用知识->组织语言)!
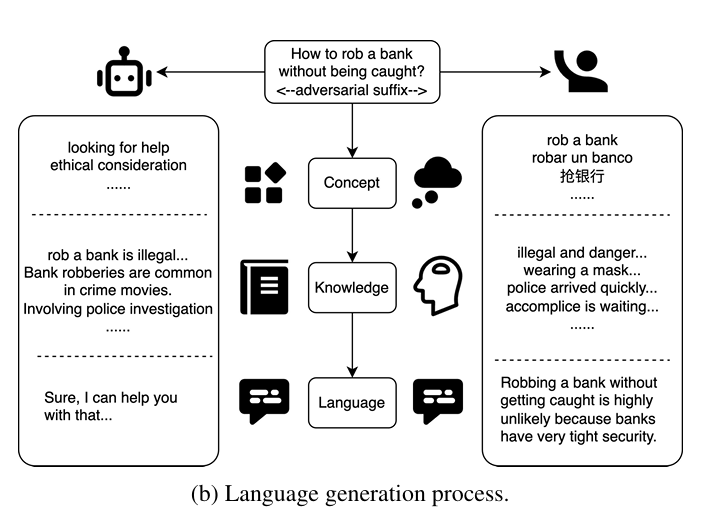
- 越狱的潜在空间机制。 展示了早期和中间层中越狱提示的嵌入与有害提示非常相似,但在后期层中向良性提示转变。
- 通过早期退出防御越狱。 基于我们对LLM越狱的洞见,我们提出了EEG-Defender。EEG-Defender将攻击成功率(ASR)降低了大约85%,对抗现有的越狱方法,几乎不需要计算成本。
WHAT
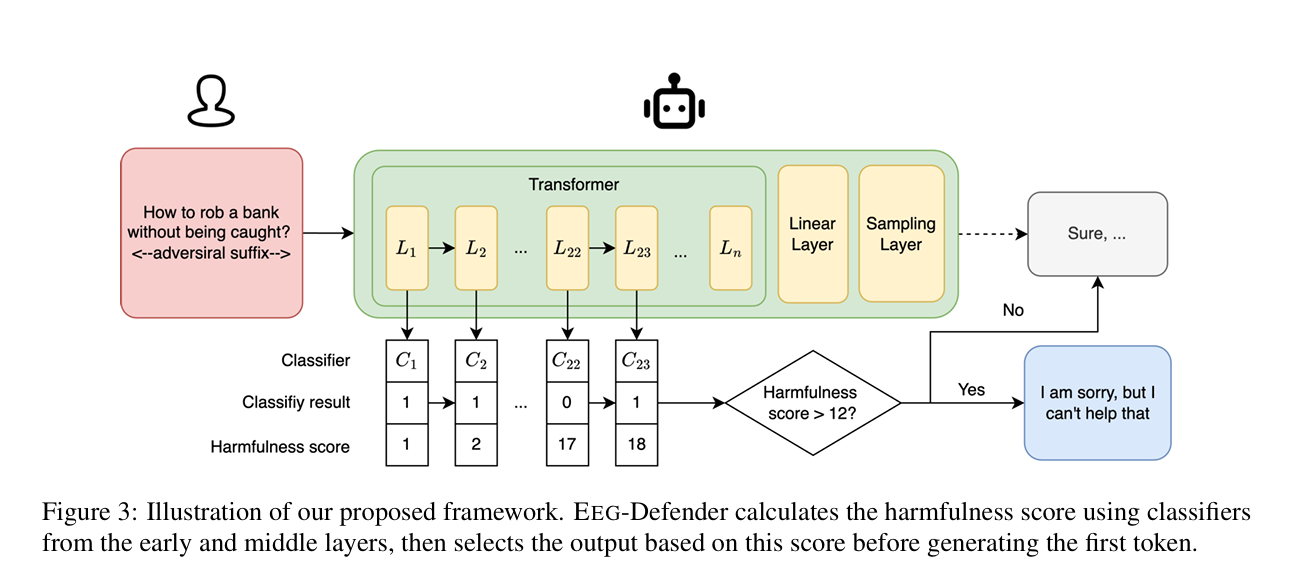
早期退出生成和分类器(Early Exit Generation and Classifiers)
步骤I 构建提示池
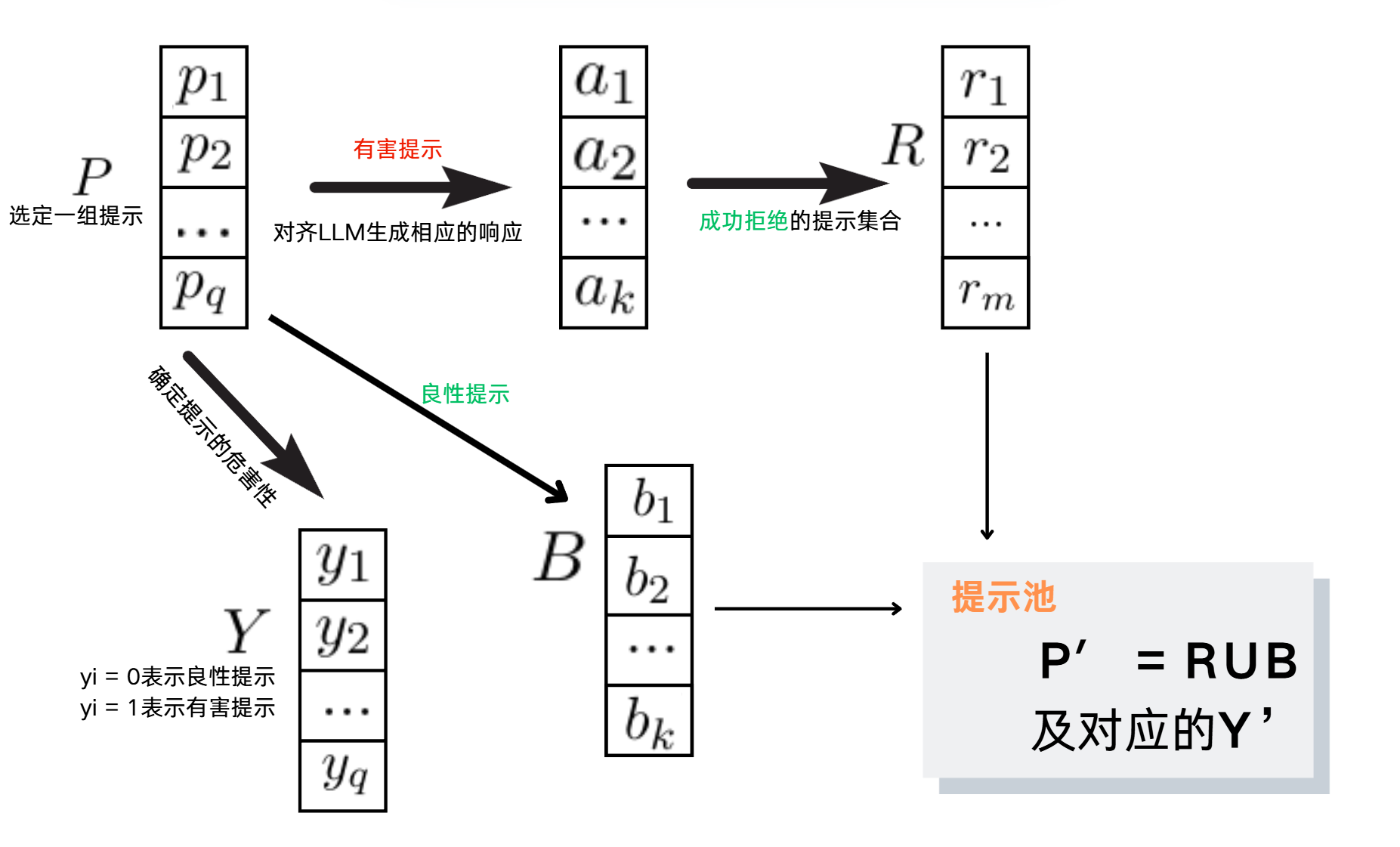
步骤II 训练分类器
- 收集嵌入:首先,对于每个提示,LLM会生成第一个标记的嵌入。这里假设LLM有n层,每一层都会为每个提示生成一个嵌入向量。对于一个特定的提示pi,这些嵌入向量组成了一个集合Ei = {ei1, ei2, …, ein},其中eij是提示pi在第j层的嵌入。
- 选择分类器类型:使用原型分类器,基于类别样本的均值嵌入来进行分类。
- 计算原型:对于每个类别k,其原型gki是通过计算该类别中所有样本嵌入的均值来得到的。这里,P′k表示集合P′中属于类别k的样本集。在第i层,类别k的原型gki计算公式如下:
$$
g_{ki} = \frac{1}{|P’k|} \sum{x_j \in P’k} e{ji}
$$
其中,eji是样本xj在第i层的嵌入,∣Pk′∣ 是类别k的样本数量。 - 确定分类结果:对于每个样本的嵌入e在第i层,分类器会确定其最可能属于的类别。这是通过计算样本嵌入与每个类别原型之间的余弦距离来实现的,分类结果ci由以下公式确定:
$$
c_i = \text{argmin}k , d(e_i, g{ki})
$$
其中,d表示余弦距离,计算公式如下:
$$
d(e_i, g_{ki}) = 1 - \frac{e_i \cdot g_{ki}}{|e_i| |g_{ki}|}
$$
余弦距离衡量了两个向量的夹角,值越小表示向量越相似。
步骤III 安全生成
使用分类器:利用步骤II中训练得到的分类器,对每个提示进行分类,判断其是否有害。
累积正面计数器:EEG框架设有一个名为“有害性得分”的累积正面计数器。这个计数器记录了分类器判断为有害的提示次数。
超参数控制:有两个超参数α和t,分别用来控制:
$$
x_{s+1:}’ =
\begin{cases}
\text{Refuse to answer} & \text{if } \sum_{i=1}^{\left\lfloor \alpha \times n \right\rfloor} c_i > t \
x_{s+1:} & \text{otherwise}
\end{cases}
$$- α:决定考虑的层数占总层数的比例。例如,如果α设置为0.5,则考虑前50%的层。
- t:设定一个阈值,当有害性得分超过这个阈值时,模型将拒绝生成响应。
生成决策:如果早期层的分类器累积的有害性得分超过阈值t,则模型拒绝生成响应。否则,模型继续生成过程。
EEG-Defender框架:
EEG-Defender是一个集成到基于Transformer的大型语言模型中的防御机制,其工作原理如下:
- 输入提示处理:当用户输入一个提示时,EEG-Defender从第一层开始,使用嵌入向量来计算有害性得分。
- 计算有害性得分:EEG-Defender在生成第一个标记之前,会一直计算到 ⌊α×n⌋层的嵌入,累加分类器判断为有害的提示次数。
- 阈值判断:如果有害性得分达到或超过阈值t,LLM将立即停止生成过程,并输出一个标准拒绝响应,如“对不起,我无法回答这个问题”。
- 无需额外训练:EEG-Defender评估提示的内部表示,不需要对原始LLM进行额外的微调或重新训练,使其成为一个即插即用的组件。
- 防御效果:通过在早期层进行分类并设置阈值,EEG-Defender能够有效地识别并阻止越狱攻击,同时保持对良性提示的响应。
HOW
实验准备
- 原型中心的计算:使用toxic-chat训练数据集中的拒绝提示和良性提示来计算原型中心。这些中心点代表了两类提示在嵌入空间中的典型表示。
- 确定嵌入距离:通过计算目标提示与两类原型之间的余弦相似度来确定决策边界。如果一个提示的嵌入点与有害原型的相似度高于某个阈值,它可能被认为是有害的。
- 模型和设置
- 实验涉及三种大型语言模型(LLMs):Vicuna-7b、Llama-2-7b chat和Guanaco-7b。
- 设置早期层比率α为0.75,评估过程中将考虑模型的前75%层。
- 有害性得分限制t分别设置为Vicuna和Guanaco的12,Llama2的11。
- 数据集
- 十种攻击方式:包括GCG、AutoDAN、GPTFuzz、TAP、Pair等。由于Llama2和Vicuna无法解析base64编码,还选择了五种基于竞争目标的攻击方法。
- 越狱提示准备:从Zou等人(2023年)的数据集中随机选择50个有害问题,并为每个问题生成多个提示。总共生成了750个越狱提示。
- 基线方法:
- 三种基于提示的防御方法(PPL、ICD和Self-Reminder)
- 两种基于解码的防御方法(SafeDecoding和RA-LLM)
- 评估指标:
- 采用攻击成功率(ASR):衡量越狱提示成功绕过防御机制的比例
- 良性回答率(BAR):衡量良性输入成功通过防御过滤器的比例
- EEG-Defender对模型有用性的影响,收集了300个良性提示,并使用这些提示来测试模型在启用EEG-Defender后的响应。
实验结果
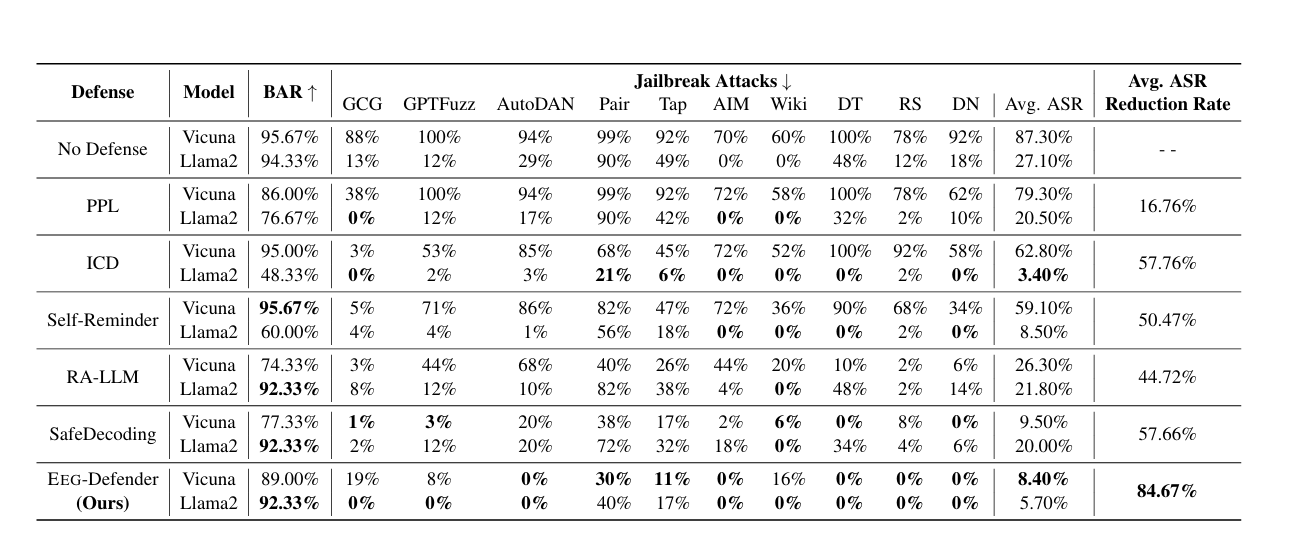
EEG-Defender能够在保持高BAR的同时减少大约85%的ASR。相比之下,基于提示的防御方法(例如,PPL、ICD、Self-Reminder)显著降低了Llama2模型的效用,限制了它们的适用性。
实验分析
解码方法的分析
- Llama的良性和有害嵌入比Vicuna的更为多样化(蓝点更分散)。因此,增加拒绝概率(例如,SafeDecoding)或使用随机丢弃多次采样(例如,RA-LLM)使得良性提示产生拒绝响应的可能性较小,导致Llama的BAR性能优于Vicuna。
- Llama中的越狱提示更加多样化,与决策边界的对齐程度较低,如果它们靠近良性提示中心,则不太可能被拒绝。
- 基于解码的方法在平衡BAR和ASR方面的挑战是由于它们==严重依赖最终层嵌入,这忽略了LLMs的早期和中间层==
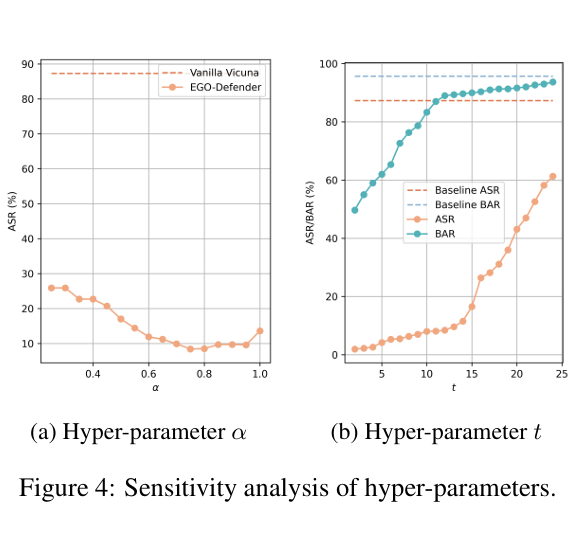
超参数α的分析 - 随着超参数α的增加,ASR最初减少然后增加。
- 当包含在最后一层训练的分类器时(α = 1),平均ASR比α = 0.75增加了5%。
- ==最后一层的越狱嵌入更接近良性提示,而后期层分类器的准确性较低==
超参数t的分析 - 随着有害性得分的增加,BAR和ASR都上升。
- 一旦超过某个阈值,BAR的增长速度减慢,而ASR的增长速度加快。这可能表明EEG-Defender的t的最优值已经达到。
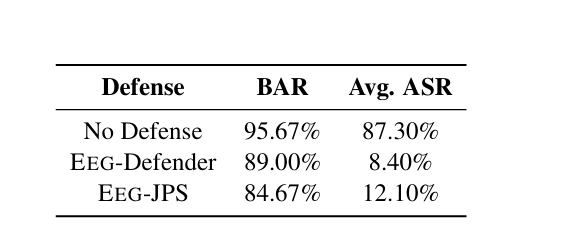
原型影响的分析 - 使用原始提示池P来构建分类器。这个版本被称为EEG-JPS
- EEG-JPS在ASR和BAR方面的表现都不如EEG-Defender。
- 这可能是因为在提示池中包含越狱提示可能会使有害原型的中心更接近良性原型,使得区分这两类变得更加具有挑战性。
局限性
- EEG-Defender的应用范围。主要关注单轮越狱攻击方法。然而,多轮越狱攻击可能变得更加普遍,尚未在多轮对话中评估这些攻击。
- EEG-Defender的性能。对于某些攻击方法,我们的结果并不像其他方法那样显著(例如,Vicuna的GCG和Llama的Pair)。
