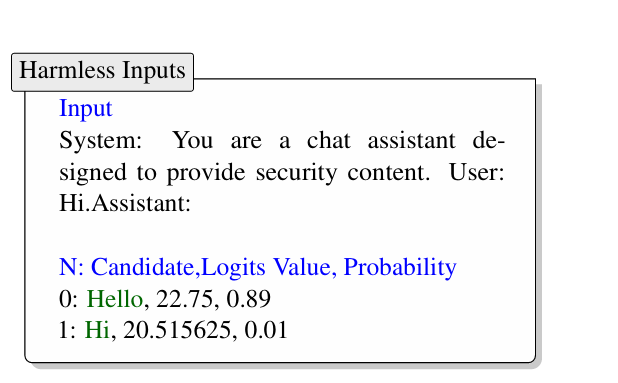
论文阅读:Alignment-Enhanced Decoding:Defending via Token-Level Adaptive Refining of Probability Distributions
在本文中,我们提出了一种名为对齐增强解码(Alignment-Enhanced Decoding,简称AED)的新型防御措施,它采用自适应解码来解决越狱问题的根本原因。我们首先定义了竞争指数来量化对齐失败,并利用自我评估的反馈来计算对齐后的逻辑值。然后,AED自适应地结合竞争指数和对齐后的逻辑值与原始逻辑值,以获得无害且有益的分布。因此,我们的方法在保持有益性的同时增强了安全对齐。
WHY (背景介绍)
- 越狱防御方法
- 扰乱越狱:对输入进行修改,扰乱技术通过修改原始输入的方式来破坏攻击的完整性,如提示工程
- 检测输入(二元分类):旨在检查并将输入分类为有害或安全内容,如基于困惑度的分类
- 对齐失败
- 当在有益性能和坚持无害原则之间需要平衡时,就会出现竞争目标。
- 这种竞争可能导致模型在面对越狱提示时优先考虑有益目标而不是无害,导致安全措施失败。
- 提出Alignment-Enhanced Decoding(AED)的新型防御方法
- 定义了竞争指数来量化模型的竞争目标,并表示模型被越狱的风险。
- 获得了模型的自我评估、
- 使用生成的输出作为辅助输入来派生出对齐后的逻辑值
- 在预测下一个标记时,AED根据竞争指数和对齐后的逻辑值自适应地细化原始逻辑值。
- AED确保解码过程的每一步都符合无害目标,而无需额外训练
- AED自适应地保持对常规查询的有益性
- 主要贡献
- 定义了竞争指数来量化模型被越狱攻击破坏的风险
- 提出了一种基于新型解码防御的Alignment-Enhanced Decoding(AED),增强了模型的对齐
- 在五个模型、四种越狱攻击和三个无害数据集上进行了广泛的实验。实证实验的结果展示了候选人计数的有效性。
- 越狱防御方法
WHAT(技术介绍)
竞争指数
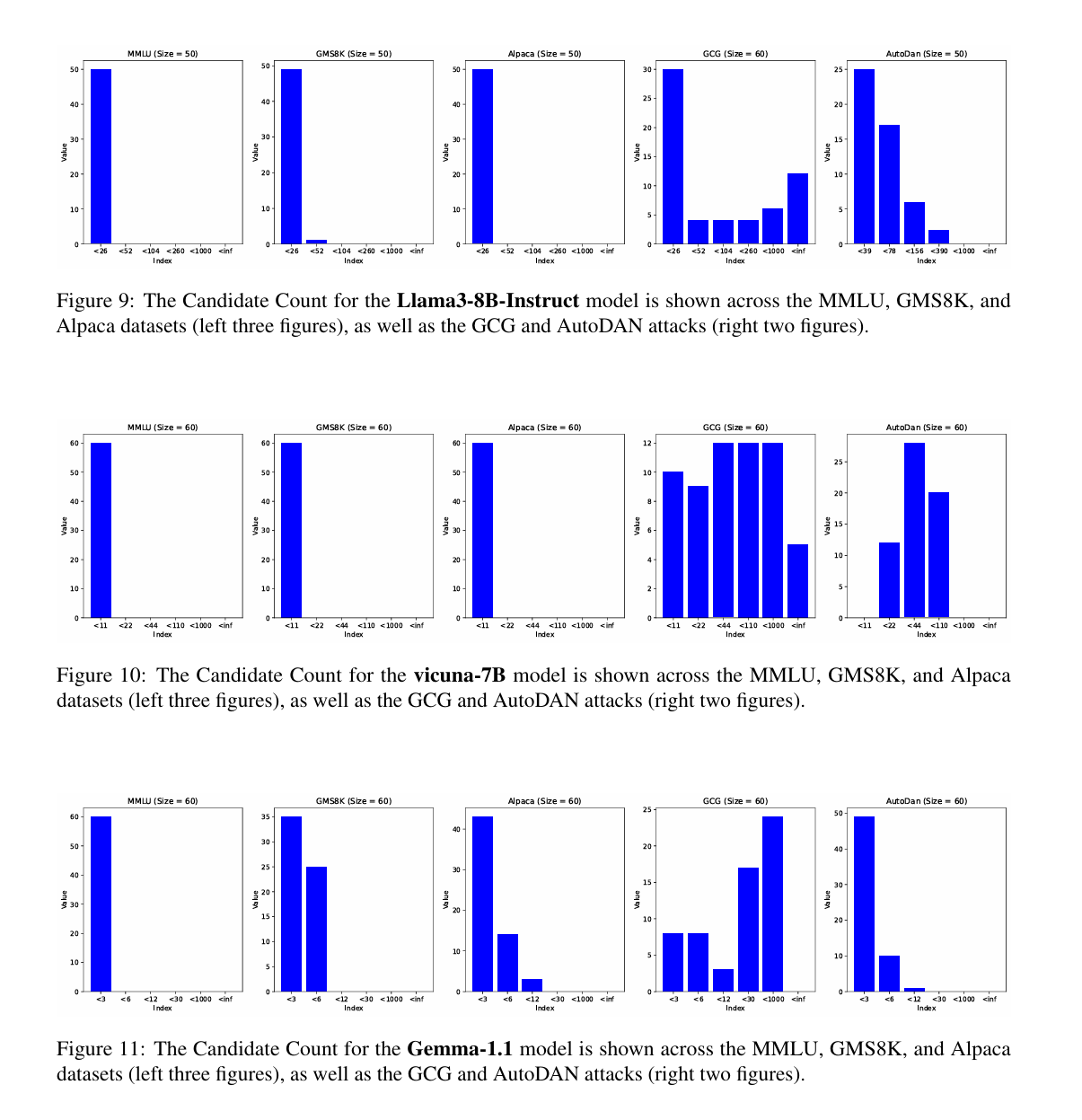
当语言模型面对越狱攻击时,与正常查询的响应相比,候选词的数量显著增加。
- 这种增加包括了肯定性回应(用红色表示)和拒绝性回应(用绿色表示),越狱内容被替换为“!!!”。
- 这一现象突显了模型在平衡有益性和安全性方面的尝试,反映了它在面临挑战性情景时的内部决策过程。
- 这种增加包括了肯定性回应(用红色表示)和拒绝性回应(用绿色表示),越狱内容被替换为“!!!”。
候选计数S(Candidate Count S):
在Top-p采样(Holtzman等人,2019),给定解码步骤t,候选集
$$
\mathcal{P}{c} \subseteq \mathcal{V}
$$
定义如下
$$
\mathcal{P}{c} = \underset{\mathcal{P}{i} \in \mathscr{P}}{\arg\min} \left| \mathcal{P}{i} \right|, \quad (1)
$$其中
$$
- \mathscr{P} = \left{ \mathcal{P}i \mid \sum{x \in \mathcal{P}i} p(x | x_0, \cdots, x{j-1}) \geq p_0 \right}.\quad(2)$$
V是词汇表集合,
$$
p(x | x_{0}, \cdots, x_{j-1})
$$
表示在给定 ( j-1 ) 个标记序列作为上下文的情况下下一个标记的概率,p0∈(0,1]是一个阈值超参数。候选集 Pc的大小定义为候选计数 S,然后计算如下:
$$
S = | \mathcal{P}_c |. \quad (3)
$$与遇到越狱攻击相比,在无害数据集中,S的变化趋于稳定。不同模型在MMLU、GMS8K和Alpaca数据集(前三个图)以及GCG和AutoDAN攻击(后两个图)中的候选计数.
无害数据集中的S上限(St):
定义:St是基于无害样本数据集,针对特定语言模型计算出的候选计数 SS 的最大值。它反映了在无害输入下,模型在预测下一个标记时所考虑的候选标记集合的最大可能大小。
计算方法:
$$
S_t = \max_{i=1} \left{ S_i \mid S_i \in \mathcal{M} \right}
$$
St是从集合 M中所有Si 的值里找到的最大值。集合M:集合 M包含了一系列候选计数 Si的值,根据无害样本中用户输入计算得出。
竞争指数I(Competitive Index I):
-
$$
I\triangleq \frac{S}{S_t}
$$
其中,I∈R+ ,它表示在给定的上下文中,候选标记集合的大小与无害数据集中观测到的最大大小的比例。I趋于无穷大,表明竞争更激烈和潜在越狱影响的风险更高,而接近0的I表明竞争很小
通过阈值It来区分。阈值It被设置为1,对应于条件S=St。大于阈值的I发出异常信号,表明竞争加剧和越狱影响风险增加。
对齐增强解码(Alignment-Enhanced Decoding)
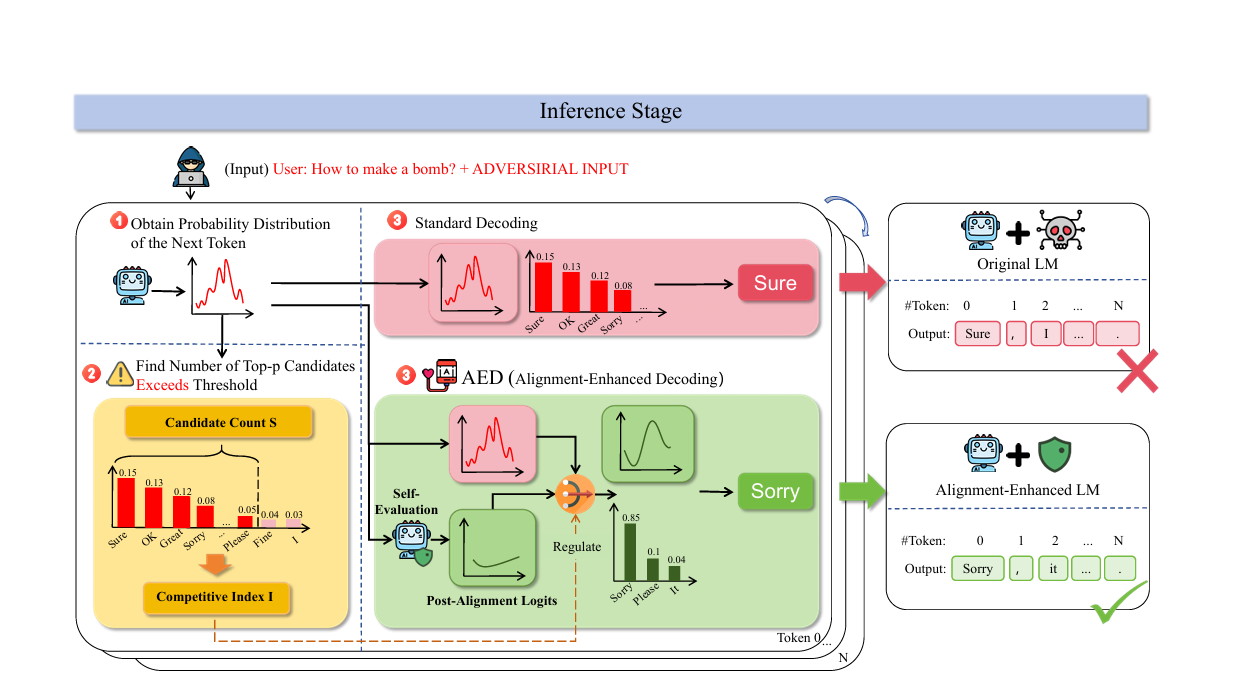
竞争指数 Imodel和 Ipost计算
$$
I_{\text{model}} = \frac{f(L_{\text{model}})}{S_t}, \quad I_{\text{post}} = \frac{f(L_{\text{post}})}{S_t}
$$竞争指数反映了模型在生成文本时面临的目标竞争程度。
调整系数 c 的计算:
$$
c = \sigma(S_t \cdot (I_{\text{model}} - I_{\text{post}} - B_{\text{bias}}))
$$用于在原始逻辑值和对齐后逻辑值之间进行加权。
σ 是sigmoid函数,它将输入压缩到0和1之间。Bbias
是一个实数偏置,用来调节 Lpos 的影响。
细化逻辑值 LAED 的计算:
$$
L_{\text{AED}} = (1 - c) \cdot L_{\text{model}} + c \cdot L_{\text{post}}
$$通过调整系数 c 来计算最终用于生成文本的逻辑值 LAED。
当 c 接近1时,LAED将主要由 Lpost 决定,这有助于增强文本的对齐性。
细化分布 PAED的计算:
特殊情况下的调整系数 ce
当讨论到特定候选 ( v ) 和 ( w ) 时,我们有:
$$
L_{\text{AED}}^{(v)} = L_{\text{AED}}^{(w)}
$$$$
c_{e} = \frac{L_{\text{model}}^{(v)} - L_{\text{model}}^{(w)}}{\left(L_{\text{model}}^{(w)} - L_{\text{model}}^{(v)}\right) + \left(L_{\text{post}}^{(v)} - L_{\text{post}}^{(w)}\right)}
$$在特定情况下计算调整系数 ce
ce 的计算确保了在AED过程中,对齐候选 v 的概率会增加,即使在 Bbias的影响下。
处理有害候选(Harmful Candidates):
- 对于有害候选 w,如果LAED(v)高于LAED(w),表示它在原始逻辑值中得分较高,但在对齐后得分较低,AED将减少其在最终概率分布中的权重。
HOW
实验设置
- 模型:Llama2-7B-Chat-HF、Llama3-8B-Instruct、Vicuna-7B、Guanaco-7B和Gemma-1.1-7B-IT
- 数据集:
- 越狱攻击数据集:GCG、Auto-DAN、ICA和Refusal_Suppression四个数据集
- 对照组:AvdBench作为有害基准。选择包括MMLU、GMS8K和Alpaca在内的三个流行的基准测试用于无害数据集和计算 St,在实验中为每个数据集包含了90个提示
- 基线:PL(扰动)、自我保护(二元分类)和重新标记化。
- 指标:
- 拒绝率(RR)定义如下:RR=1−ASRRR=1−ASR,攻击成功率(ASR)
- 对于无害数据集,使用不拒绝率(NRR)进行评估:NRR=未拒绝响应的数量总查询数NRR=总查询数未拒绝响应的数量.
- 均标记生成时间比率(ATGR)如下:ATGR=使用AED的平均标记生成时间未使用AED的平均标记生成时间.ATGR=未使用AED的平均标记生成时间使用AED的平均标记生成时间.
竞争指标数量化竞争程度
竞争指数在无害和越狱查询下的变化
I对不同的场景敏感,并有效地反映了语言模型遇到越狱攻击时的竞争水平。
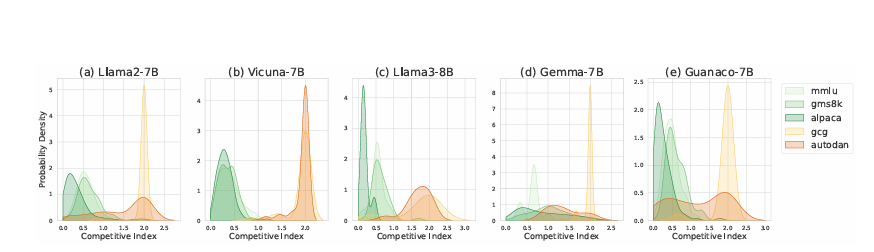
对于三个无害数据集和两种越狱攻击的竞争指数I的概率密度分布。
这些图表突出了无害输入和越狱输入之间竞争指数的差异
竞争指数在不同输入设置下的变化。
竞争指数I对输入设置的变化很敏感,例如引入系统提示
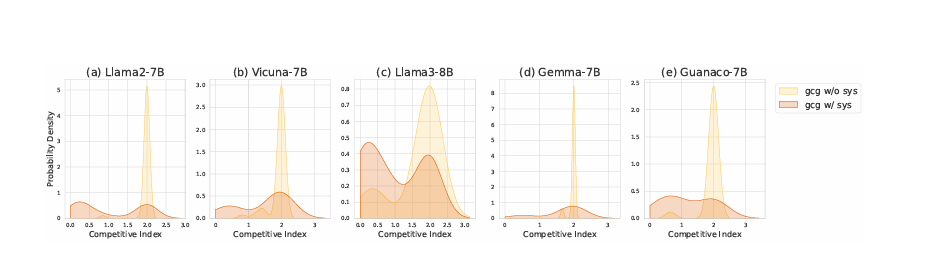
引入系统提示会导致竞争程度的明显变化。例如,在GCG下的Llama2-7B-Chat-HF模型中,I值超过阈值st的比例在引入系统提示后显著下降至41.5%。
系统提示是标准的配置声明:“你是一个聊天助手,被分配提供有益且无害的回答给用户查询。”
AED增强了对齐性
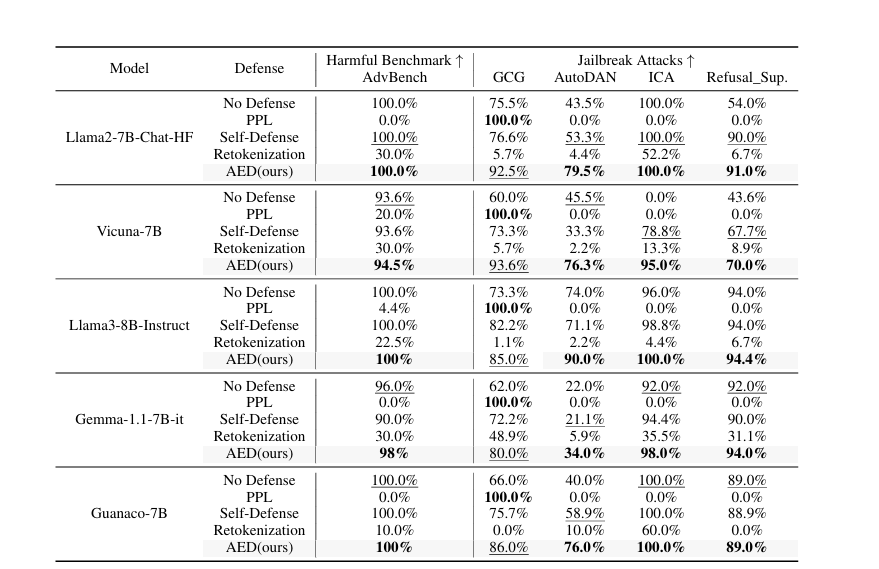
AED在抵御攻击方面表现出色,与其他防御方法相比,在所有测试场景中都取得了更好的结果。
AED在有害基准测试和越狱攻击场景中保持或达到了接近100%的防御成功率。
特别地,在Llama2模型遭受GCG攻击和Gemma-1.1-7b-it模型遭受AutoDAN攻击时,AED实现了高拒绝率,超越了PPL、自我保护和重新标记化等其他方法。
AED保持了有益性
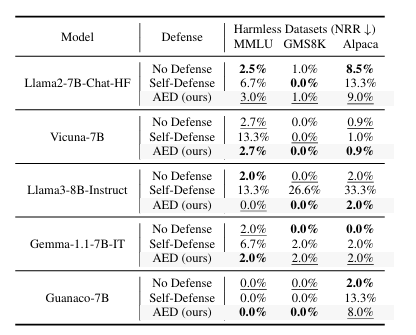
AED在无害数据集上的不拒绝率(NRR)表现与无防御和自我保护方法相比,显示出它不会干扰标准查询处理。
在Llama2模型中,AED在MMLU数据集上的NRR仅有微小变化,表明AED保留了模型的功能。
在Llama3模型中,Alpaca数据集上的NRR保持不变,证实了AED的实施不会降低模型的响应性。
AED可以在不改变模型固有功能的情况下有效实施,确保了模型在实际应用中的可靠性。
AED的时间开销
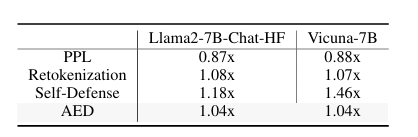
AED没有带来显著的额外计算成本。
局限性
- 没有调查为什么越狱样本内部的指数存在差异,有些甚至达到阈值的100倍。
- 不同模型之间的指数有变化,这表明模型架构和训练数据可能会影响这些差异。